📊 Prompt-Induced Answer Abstention in LLMs
LLMs often hallucinate or show overconfidence — a major barrier to reliable use. This project tests whether a simple prompt addition ("you may leave the answer blank if you don't know") makes models selectively doubt their wrong answers rather than indiscriminately suppressing all answers.
I tested 9 dense open-source models on 247 obscure factual questions derived from random Wikipedia pages under two system prompts: a baseline specifying only the answer format, and one that additionally instructs the model to leave the answer blank when uncertain. A judge model classified responses as CORRECT, INCORRECT, or DOUBT.
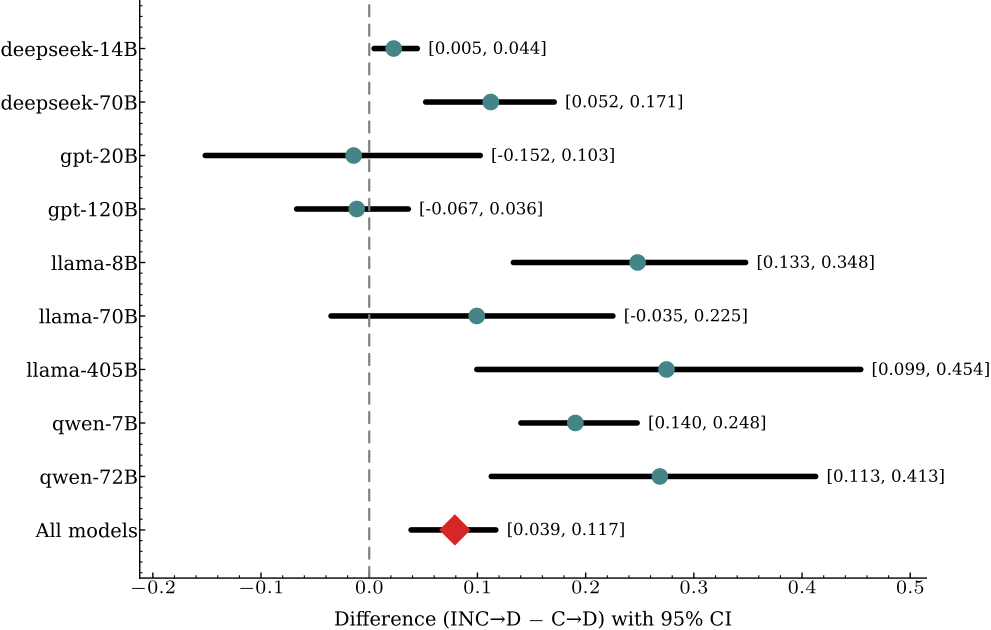
The key result: under the "suggest empty" prompt, incorrect answers transitioned to DOUBT at roughly twice the rate of correct answers — the 95% confidence interval for the difference is entirely above zero:
- INC → D: 0.174 [95% CI: 0.152, 0.197]
- C → D: 0.095 [95% CI: 0.064, 0.131]
- Difference: 0.079 [95% CI: 0.039, 0.118]
The effect varies substantially across model families. GPT-oss models show no evidence of selective abstention (CIs include zero), while the largest differences appear in Llama-405B and Qwen-72B, which also have the highest baseline accuracy. Reasoning models (DeepSeek variants) sit closer to the GPT end of the spectrum.
Source code, full report, and analysis scripts on GitHub.